
こんにちは、コンスキです。
PDFファイルには大きく分けて次の2種類があります。
- Wordなどの電子データをもとに作られたPDF
- 書類をスキャナーでスキャンして作られたPDF
このうち2つ目のスキャンによって作られたPDFに関して、困ったことがあります。
文字のコピーや文書内検索ができないという問題です。
今回はそのようなPDFファイルをtxtファイルからtxtファイルを作成する方法をご紹介します。
txtファイルにしてしまえは、文字コピーと文書内検索がどちらもできるようになります。
PDFファイルからtxtファイルを作成する
1.こちらのサイトに行きます。
2.「Choose File」と書かれたボタンをクリックして、文字を抽出したいファイルを選択します。
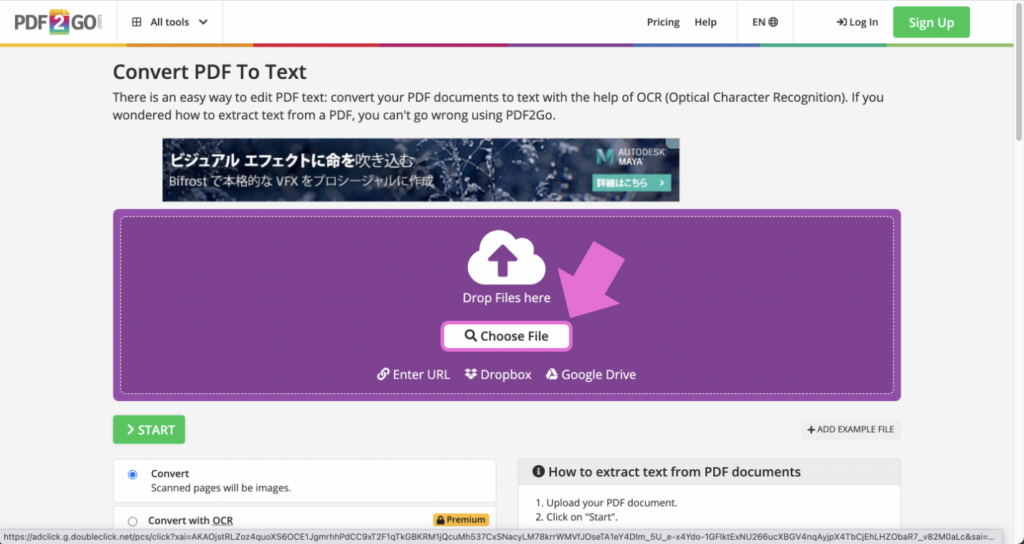
3.下に少しスクロールして、「Convert with OCR」を選択します。
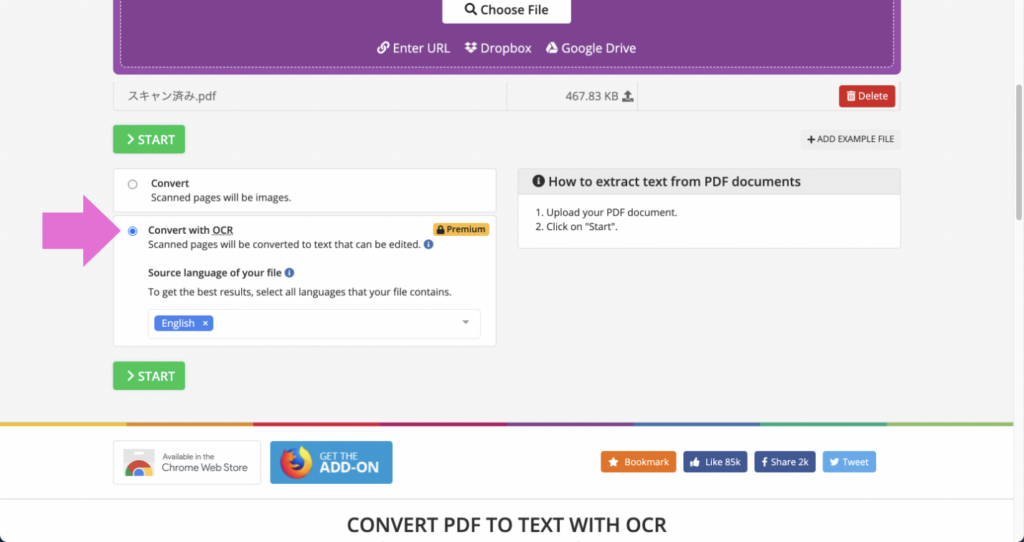
4.「▼」をクリックした後、出てきたメニューから抽出したい言語を選択します。
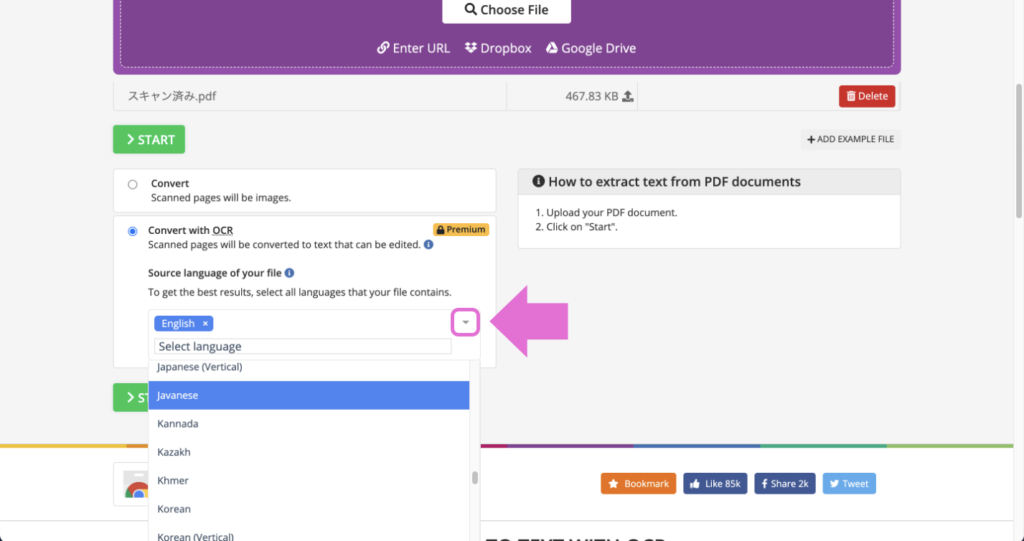
5.「START」ボタンをクリックします。

6.しばらくするとtexファイルが自動でダウンロードされます。
スペースを消す
言語の設定でJapaneseを設定した場合は、不自然なスペースが入ってしまいます。
こちらのサイトへ移動します。
「全てのスペース」にチェックを入れてから、左側のテキストボックスにtxtファイルの中身を入れてみたください。
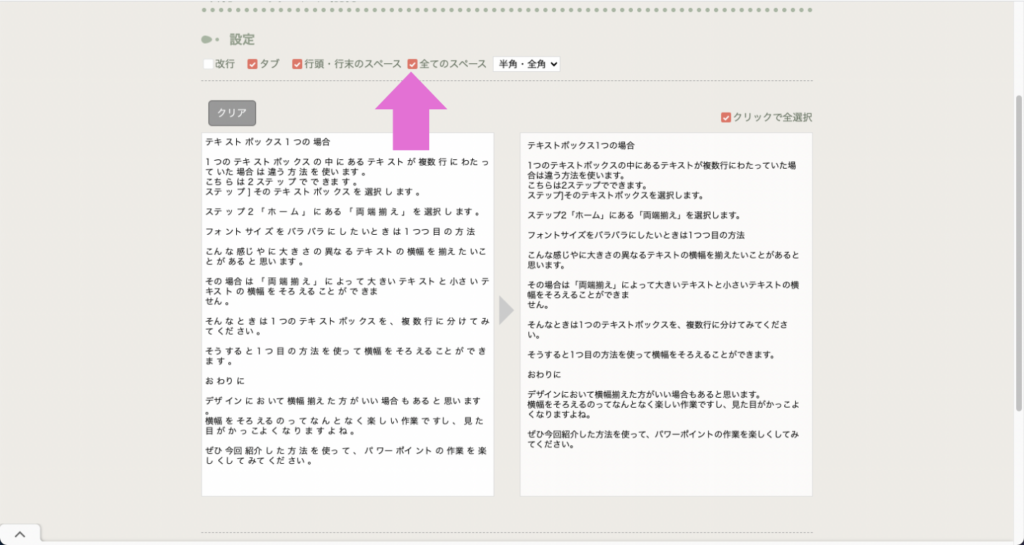
不要なスペースが消えた状態で、右側のテキストボックスに表示されます。
精度
もとのPDFファイルと、最終的に抽出した文字を比較してみます。

完璧とは言えませんが、コピーや文書内検索をするにおいては十分な精度で抽出できました。


コメント