
最近、強化学習の学習を始めました。
強化学習というと物理エンジンであるUnityでお馴染みのこーじさんを思い浮かべる方もいるのではないでしょうか。

もし、見たことがない方がいたら是非見ていただきたいです。大好きです。
この強化学習、面白いところはなんといっても成長過程だと思います。成長するのは機械なんですが、成長過程を見ているとまるで生きているかのように感じてきます。
上のこーじさんの動画を見ていただければ、100%間違いなく感じると思うのですが、かわいいんですよね。
僕が強化学習に興味を持ち始めたきっかけも、こーじさんの動画です。
初めての強化学習は迷路
「初めて」といってもまだ数えられるくらいしか、自分で実装したことはないのですが、最初にこの手で触れた強化学習の題材は迷路でした。
こちらの記事で解説してくださっているやつです。
僕にとっては決して簡単ではありませんでしたが、コメントが丁寧に書かれていてとてもわかりやすいです。一行一行意味を確認すれば、全体的にけっこう意味がわかると思います。
強化学習には種類が色々あるようで、こちらの記事で説明されていたのはQ学習と呼ばれるものでした。詳しくはこちらの記事を読んだ方が遥かにわかりやすいです。僕がやったQ学習の概要はだいたいこんな感じです。
- 迷路という環境がある
- 迷路の中を対象(エージェント)が動くと、対象はそれに応じて報酬と動いた後の状態を受け取る
- 「位置Aで行動1をしたときに10点もらえた」というように、行動によって得られた報酬によってその行動が評価されていく(このように各行動を評価した値がQ値)
- 次また同じ位置で行動するときに更新されたQ値をもとに行動を決めることで、最適な行動ができるようになる
ちょっと誤解が含まれているかもしれませんが、ふんわりと理解できました。
迷路にはスタートとゴール、壁とトラップがあります。ゴールにたどり着けば報酬が100点もらえて、トラップにたどり着けば反対に-100点の報酬です。
スタートから、ゴールかトラップに着くまでを1エピソードとして、それを何回も繰り返します。何回も繰り返すので、これまでのエピソードの行動でもらえた報酬をもとに最適な行動が行動がわかるようになります。
Q値を更新する数式を利用するのですが、僕の場合は見て強化学習に対するモチベーションが下がったので、あえてここには載せません。ぜひ、興味がある方はこちらの記事で確認してみてください。
成長していく様子を見ることがモチベーション
結局成長をしてく様子をみたい固めに強化学習をやってみている感じはあります。新しい何かを作りだしたり、何かの役に立つかもしれないという希望ももちろんあります。
でも、やっぱり強化学習で成長していく子たちを初めて見たときのインパクトがすごく印象に残っているので、第一目的はそっちです。
先ほど紹介させていただいた迷路を使った強化学習は、最終的に次のことがわかるようになっています。
- エピソードごとにもらえた報酬の合計
- その合計がエピソードを重ねるごとに多くなっていくこと
具体的には、100回分のエピソード(反復?)が終わるとこんな感じのグラフが表示されます。
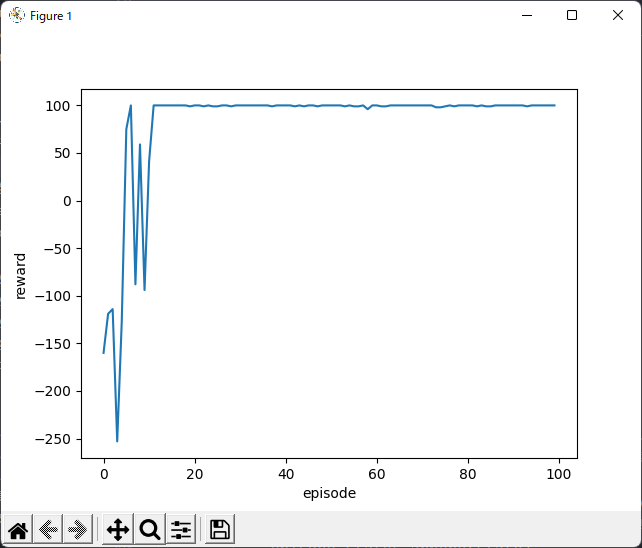
7~9回繰り返したあたり成長が著しくて、その後一度下がりますが徐々に安定して高異報酬を取れるようになります。
この成長を見届けたいと思ったのですが、そのままでは成長する様子は見られないようです。成長の様子を気にする人なんてあんまりいないと思うので当たり前かもしれません。
ちなみに、Q学習の本来の目的は総報酬をなるべく多くする行動の選び方
を模索することだそうです。
とはわかりつつも、成長していく様子が見られるように、少し手を加えてみました。
Gがゴール地点で、Tがトラップ、Wが壁を表しています。とっても簡易的ですが4回目あたりで初めてゴールに到達して、それからすぐにゴールへたどり着けるようになった様子が確認できました。
パソコンにかかる負荷がとても高いようで、最後の方は処理が追いつかずにバグが出てしまっています。強化学習は条件分岐よりもforやwhlile文による繰り返し処理のほうが多いため、GPUを使って計算するべきでした。
Unreal Engineで強化学習ができるようになりたい
ライブラリのようなものがあるということもあり、Unityで強化学習をやっている方はよく見かけますが、Unreal Engineで強化学習をやっている動画はあまり拝見したことがありません。
Unreal Engineを使って、MetaHumanの動きなんかを成長させられたらおもしろのではないかと考えています。

Unreal Engineにはブループリントと呼ばれる、ノーコードでプログラミングできる機能が備わっていて、普段はとても便利な機能なのですが、強化学習をする上においては逆にやりづらいかもしれないので、C++を使って直接コードを書いたほうがいいかもしれません。
できたらすぐに公開するのでぜひご覧ください。


コメント